How Node.js Handles Multiple Requests with a Single Thread
S
Learning web development in public. Writing simple, real-world explanations about web development concepts. Helping beginners understand why things work, not just how.
Search for a command to run...
Learning web development in public. Writing simple, real-world explanations about web development concepts. Helping beginners understand why things work, not just how.
No comments yet. Be the first to comment.
Every day, millions of users upload photos, videos, stories, and reels to Instagram. From a user's perspective, the process appears simple: select media, apply filters, add a caption, and tap "Post."
Building Offline-First Messaging Apps: How Messages Work Without Internet Modern messaging applications have transformed the way people communicate. Whether it's chatting with friends, collaborating w
In this article we'll explore about the Expo Router and React Navigation and answer which one to use in 2026. If you build mobile apps using React Native, one thing becomes obvious very quickly: Navig
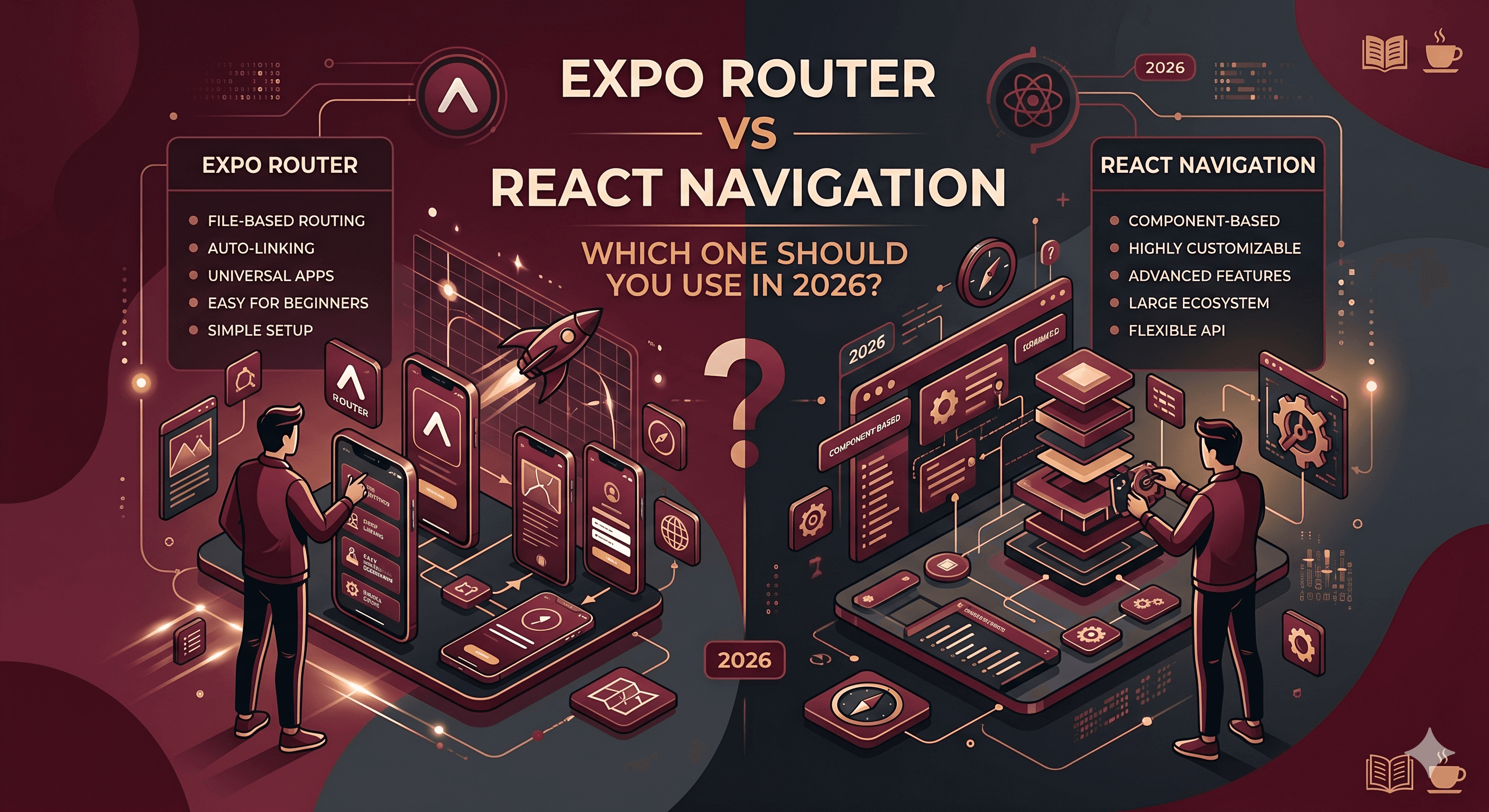
Modern mobile apps are no longer just a collection of screens connected together. Apps like Instagram, WhatsApp, Uber, and Netflix operate at massive scale with millions of users, real time systems, o
In this article we'll be exploring react.js and the things of react.js that makes it popular and stand out among other libraries ( no fight over library vs framework ). We'll go through: What problem
Shkaai
68 posts
One of the most common and confusing questions for beginners is:
If Node.js is single-threaded, how does it handle thousands of requests at the same time?
At first glance, this sounds impossible. In many traditional systems, handling multiple users usually means using multiple threads. But Node.js takes a completely different approach.
Let’s understand this step by step in a clear and detailed way.
Node.js executes JavaScript code on a single main thread. This means:
Only one piece of JavaScript code runs at a time
There is no parallel execution of JavaScript like in multi-threaded environments
All synchronous code runs line by line
console.log("Start");
console.log("Processing...");
console.log("End");
Output:
Start
Processing...
End
This behaviour is straightforward. The code runs from top to bottom.
However, this creates a concern: If one task takes a long time, will everything else stop?
If Node.js worked only like this, it would not scale. But this is where its architecture becomes powerful.
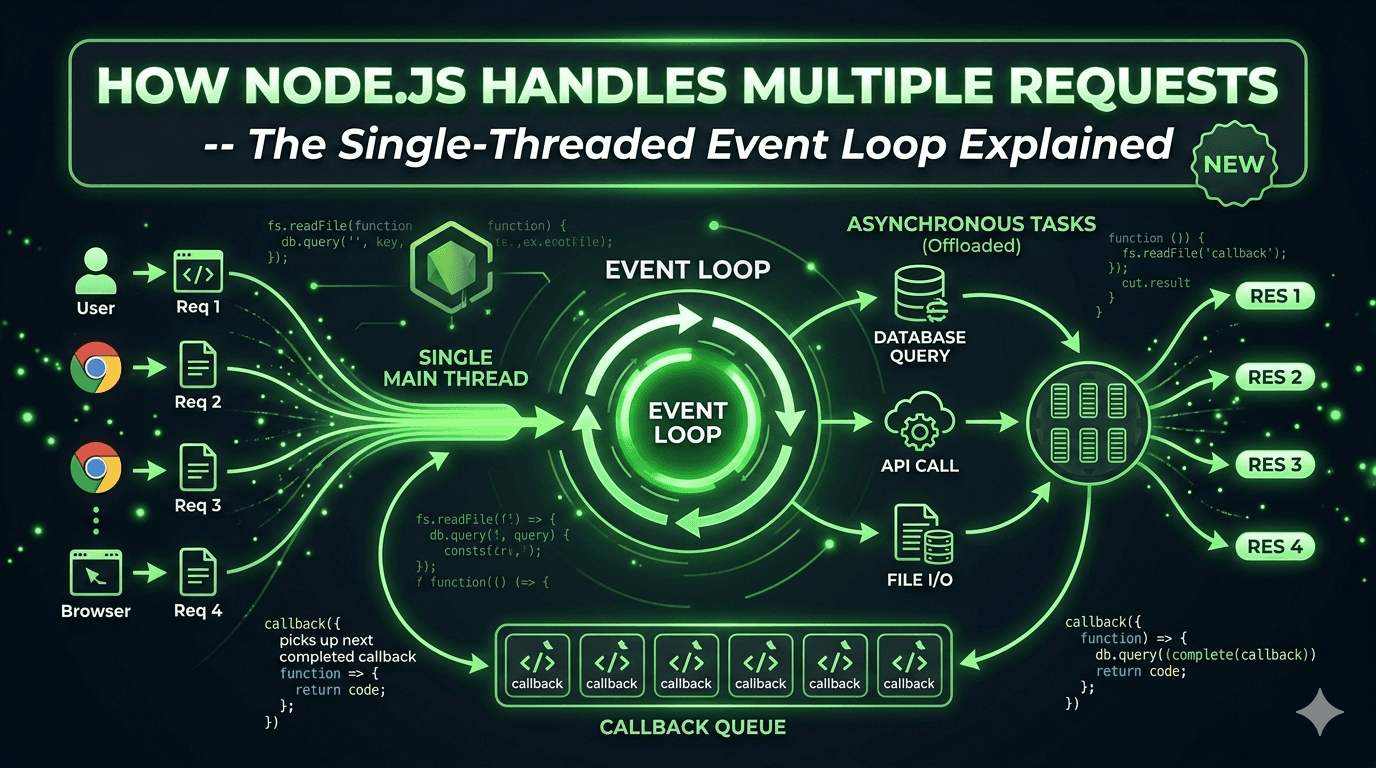
The Event Loop is the core mechanism that allows Node.js to handle concurrency.
Instead of blocking the main thread while waiting for operations like file reading or database queries, Node.js uses an event-driven system.
Node.js does not wait for slow operations. It registers them and moves on.
console.log("Start");
setTimeout(() => {
console.log("Timeout finished");
}, 2000);
console.log("End");
Output:
Start
End
Timeout finished
Here is what actually happens:
"Start" is printed
The setTimeout is handed off to the system
Node.js continues execution and prints "End"
After 2 seconds, the callback is pushed into a queue
The Event Loop picks it up and executes it
The Event Loop constantly checks:
Is the main thread free?
Are there any completed tasks waiting?
If yes, it processes them.
Node.js uses a library called libuv to manage asynchronous operations.
When Node.js encounters tasks such as:
File system operations (reading/writing files)
Database queries
Network requests (API calls)
Timers
It does not handle them directly on the main thread.
Instead, it delegates these tasks to:
The operating system
A thread pool managed by libuv
A request comes in
Node.js identifies if the task is blocking or non-blocking
If it is time-consuming, it sends it to a background worker
The main thread continues handling other tasks
Once the background task is complete, its callback is placed in a queue
The Event Loop executes the callback when the main thread is free
This design ensures that the main thread is never stuck waiting.
Let’s understand this with a real-world scenario.
Imagine three users send requests to a server:
User A: requests a simple response (fast)
User B: requests data from a database (slow)
User C: requests another simple response (fast)
User A is processed
User B starts and blocks the server
User C has to wait until User B is done
This leads to delays and poor performance.
User A is processed immediately
User B’s database request is sent to a background worker
User C is processed without waiting
When User B’s data is ready, the response is sent
Node.js can keep accepting and processing new requests while waiting for slower ones to complete.
This is called non-blocking I/O.
Node.js is designed to handle large numbers of concurrent connections efficiently.
1. Non-blocking architecture Node.js does not stop execution for slow operations.
2. Event-driven model Instead of creating new threads for each request, it uses events and callbacks.
3. Low memory usage Traditional servers create a new thread per request, which consumes memory. Node.js avoids this.
4. Efficient handling of I/O-heavy tasks Most web applications involve I/O operations (API calls, database queries), which Node.js handles very well.
REST APIs
Real-time applications (chat apps, notifications)
Streaming services
Microservices architecture
In such cases, the single thread can become a bottleneck.
Here is the complete flow of how Node.js handles multiple requests:
A client sends a request
Node.js receives it on the main thread
If the task is fast, it processes it immediately
If the task is slow, it delegates it to background workers
Node.js continues handling other incoming requests
Once background tasks are complete, callbacks are queued
The Event Loop executes them when the main thread is available
This cycle continues continuously, allowing Node.js to serve many users efficiently.
Node.js uses a single thread for executing JavaScript
It relies heavily on asynchronous programming
The Event Loop manages task execution
Slow operations are handled outside the main thread
Multiple requests are processed without blocking
Node.js handles multiple requests efficiently by using a single thread combined with an event loop, non-blocking operations, and background workers.